Selected Publications
* indicates equal contribution
|

|
OmniReset: Emergent Dexterity via Diverse Resets and Large-Scale Reinforcement Learning
Patrick Yin*,
Tyler Westenbroek*,
Octi Zhang,
Joshua Tran,
Ignacio Dagnino,
Eeshani Shilamkar,
Numfor Mbiziwo-Tiapo,
Simran Bagaria,
Xinlei Liu,
Galen Mullins,
Andrey Kolobov,
Abhishek Gupta
ICLR 2026
project page
/
arXiv
Diverse resets and large-scale RL for sim2real dexerity
|

|
SGFT: Rapidly Adapting Policies to the Real-World via Simulation-Guided Fine-Tuning
Patrick Yin*,
Tyler Westenbroek*,
Simran Bagaria,
Kevin Huang,
Ching-An Cheng,
Andrey Kolobov,
Abhishek Gupta
ICLR 2025
project page
/
arXiv
Sim2real value function transfer for real world RL
|

|
Simulation Distillation: Pretraining World Models in Simulation for Rapid Real-World Adaptation
Jacob Levy*,
Tyler Westenbroek*,
Kevin Huang,
Fernando Palafox,
Patrick Yin,
Shayegan Omidshafiei,
Dong-Ki Kim,
Abhishek Gupta,
David Fridovich-Keil
RSS 2026
project page
/
arXiv
Sim2real world model transfer for real world RL
|
|
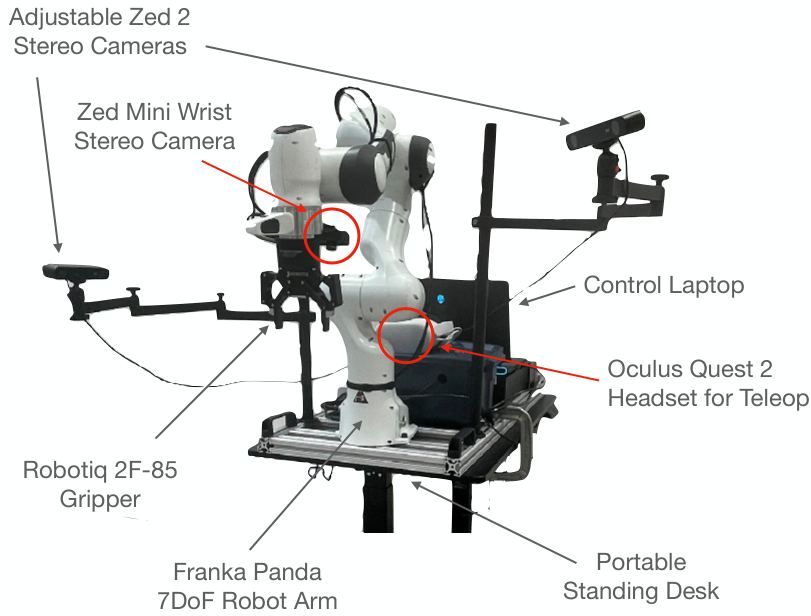
DROID: A Large-Scale In-the-Wild Robot Manipulation Dataset
Alexander Khazatsky*,
Karl Pertsch*, ...,
Patrick Yin, ...,
Sergey Levine,
Chelsea Finn
RSS 2024
project page
/
arXiv
Community driven teleop dataset
|
|
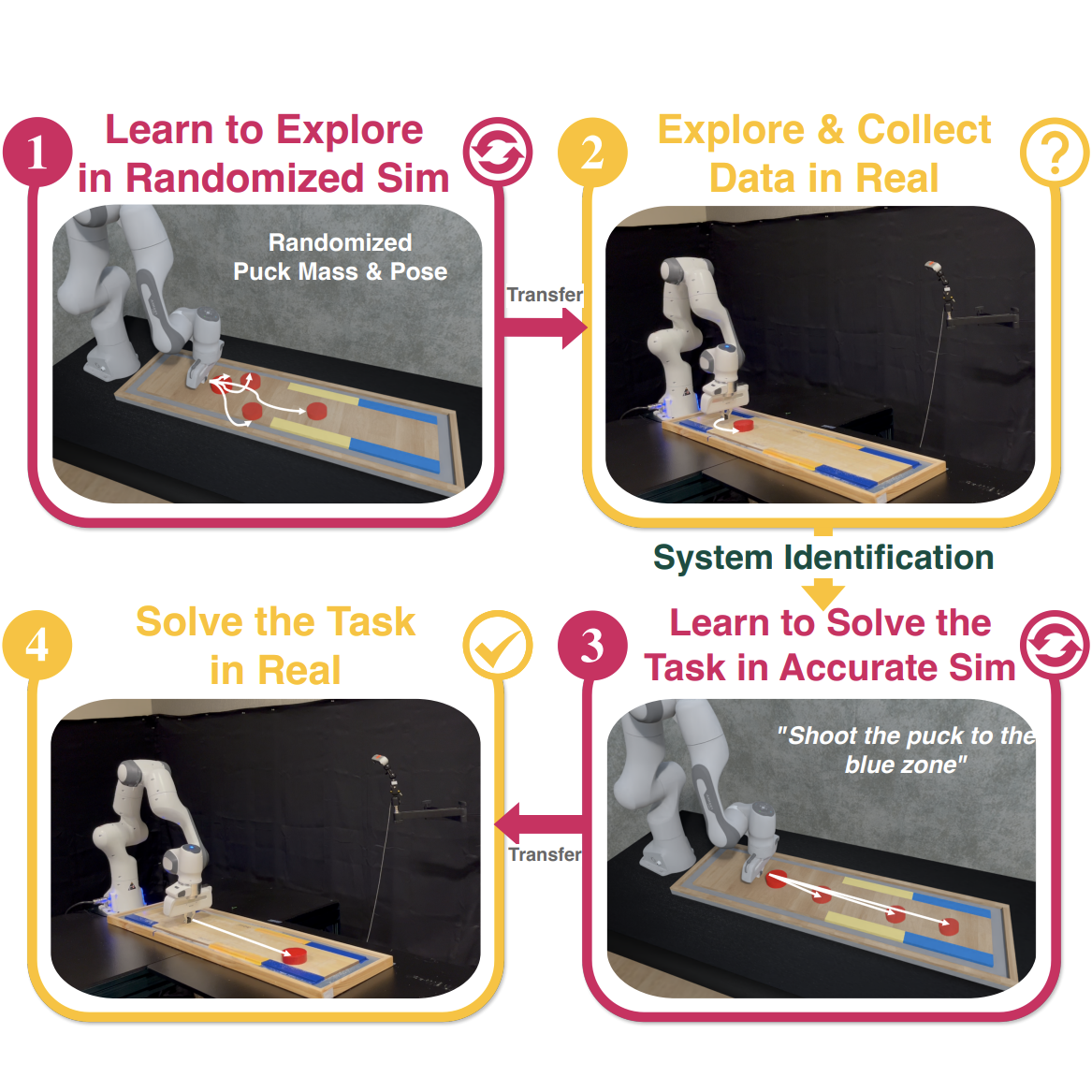
ASID: Active Exploration for System Identification and Reconstruction in Robotic Manipulation
Marius Memmel,
Chuning Zhu,
Andrew Wagenmaker,
Patrick Yin,
Dieter Fox,
Abhishek Gupta
ICLR 2024 (Oral Presentation)
project page
/
arXiv
Active sysid for sim2real
|
|
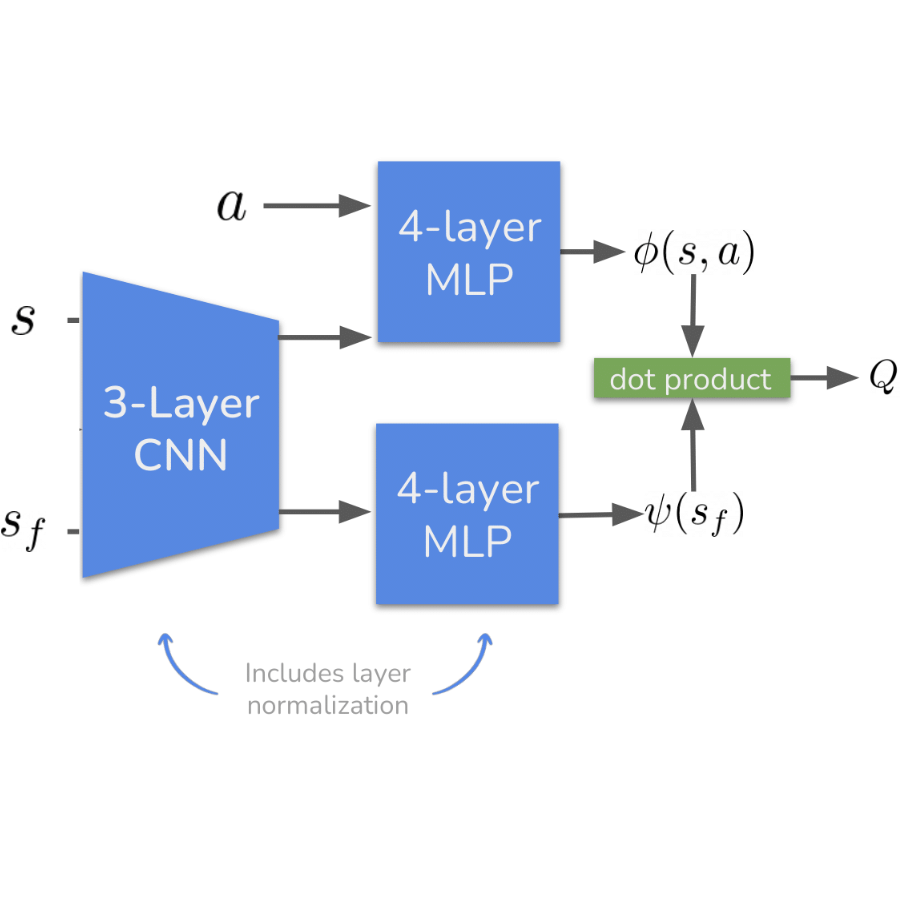
Stabilizing Contrastive RL: Techniques for Robotic Goal Reaching from Offline Data
Chongyi Zheng,
Benjamin Eysenbach,
Homer Rich Walke,
Patrick Yin,
Kuan Fang,
Ruslan Salakhutdinov,
Sergey Levine
ICLR 2024 (Spotlight Talk)
project page
/
arXiv
Contrastive offline RL
|
|
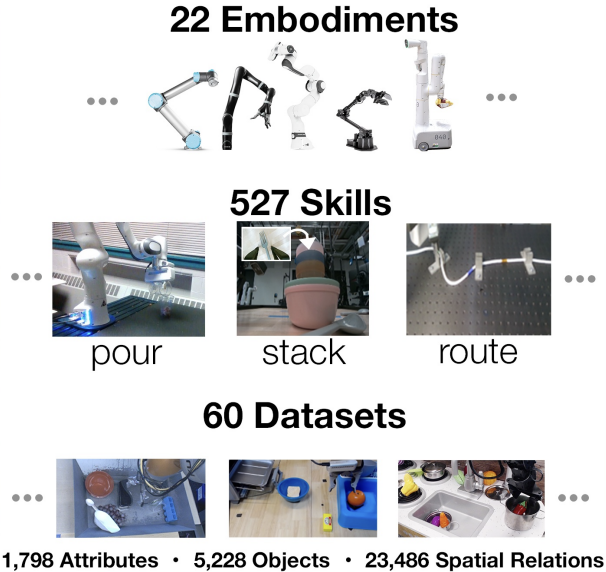
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
Open X-Embodiment Collaboration, ...,
Patrick Yin, ...
ICRA 2024 (Best Paper)
project page
/
arXiv
Large community driven teleop dataset
|
|
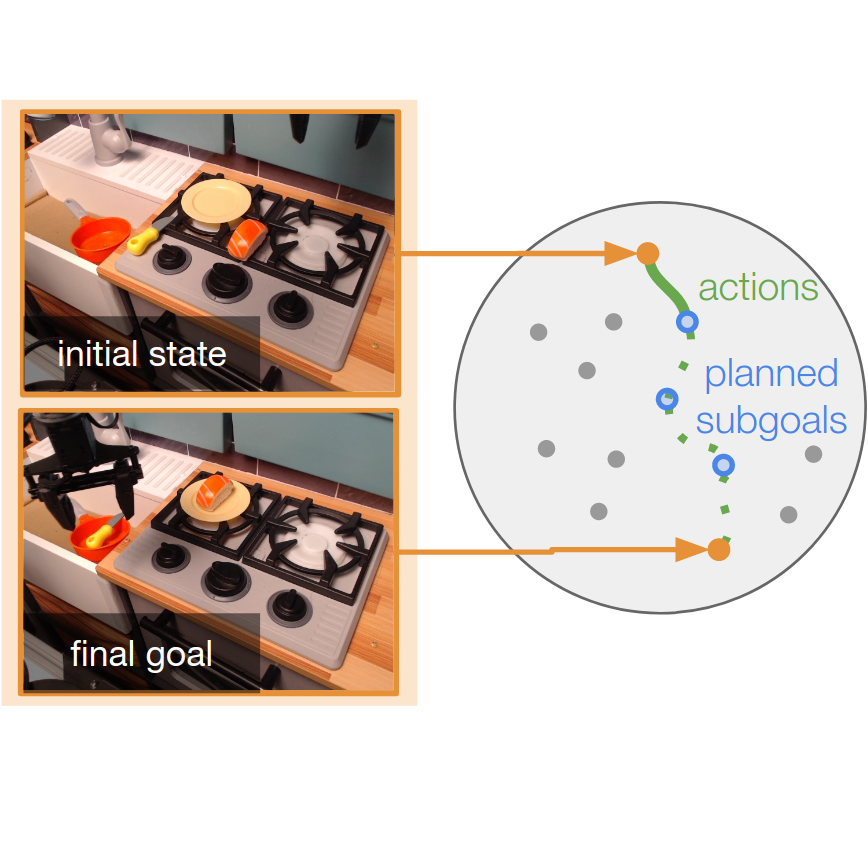
Generalization with Lossy Affordances: Leveraging Broad Offline Data for Learning Visuomotor Tasks
Kuan Fang,
Patrick Yin,
Ashvin Nair,
Homer Rich Walke,
Gengchan Yan,
Sergey Levine
CoRL 2022 (Oral Presentation)
project page
/
arXiv
Latent space planning for goal-conditioned real-world RL
|

|
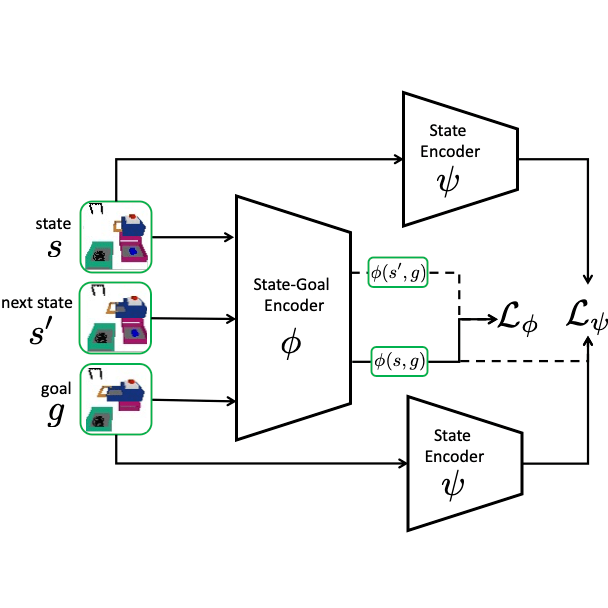
Planning to Practice: Efficient Online Fine-Tuning by Composing Goals in Latent Space
Kuan Fang*,
Patrick Yin*,
Ashvin Nair,
Sergey Levine
IROS 2022
project page
/
arXiv
Planning for goal-conditioned real-world RL
|
|
Bisimulation Makes Analogies in Goal-Conditioned Reinforcement Learning
Philippe Hansen-Estruch,
Amy Zhang,
Ashvin Nair,
Patrick Yin,
Sergey Levine
ICML 2022
project page
/
arXiv
Bisimulation-based offline RL
|
Website template from
Jon Barron.
|
